John's Technical Blog
JMeter in IntelliJ IDEA on Mac OS X
2016-08-12
Quick Answer
Manually add the JMeter path at
Preferences » Other Settings » JMeter » JMeter home directory
Long Answer
I wanted to be able to launch JMeter scripts from within IntelliJ IDEA. This is the process I went through to make this happen:Install JMeter
Having already installed Homebrew, JMeter can be easily installed with the command
brew install jmeter
Install JMeter Plugin in IntelliJ IDEA
Preferences » PlugIns » Search for JMeter » Select JMeter plugin » install » restart IntelliJConfigure JMETER_HOME
This is where the troubleshooting needed to start. For the quick solution, see the first section. Otherwise, this is the process I went through:Ideally, one would want things to "just work" after installing JMeter and the plugin. Unfortunately, when I created my first JMeter Run Configuration in IntelliJ, I got the message in the dialog box:
Run Configuration Error: JMeter not found
I eventually found a dialogue box under
Preferences » Other Settings » JMeter
with a helpful indicator that
JMETER_HOME is used by default
Sure enough, when I ran the env command in a Terminal, JMETER_HOME was not there.
To find out what my JMeter home directory was, I did the following in the Terminal
$ which jmeter
/usr/local/bin/jmeter
$ cat /usr/local/bin/jmeter
#!/bin/bash
exec "/usr/local/Cellar/jmeter/3.0/libexec/bin/jmeter" "$@"
So, based on some other information I gathered, the home directory was just above the "bin" directory.
My first attempt was to add the following line to my .bash_profile:
export JMETER_HOME=/usr/local/Cellar/jmeter/3.0/libexec
Sadly, I found this didn't work after rebooting and confirming that it showed up when the env command was executed in the Terminal.
I eventually ran across Setting global environment variables in IntelliJ IDEA and other test config goodies, from which I learned that environment variables are not automatically passed to GUI applications in Mac OS X. Nonetheless, Update 2 in the article looked promising.
I then added this line to .bash_profile:
launchctl setenv JMETER_HOME /usr/local/Cellar/jmeter/3.0/libexec
Again, to my frustration, I found that after rebooting and confirming that launchctl getenv JMETER_HOME displayed the correct value in the terminal, that this only worked in IntelliJ when I started IntelliJ, quit completely, and then started it again. I have no idea why the environment variable only seems to get read on the second startup.
So, for my final answer, I just had to go with the manual solution of adding the JMeter home path as an Override in the dialogue box found at:
Preferences » Other Settings » JMeter » JMeter home directory

Extract the icon from an APK file
2016-08-05
Using the
apk-parser library (https://github.com/caoqianli/apk-parser), I developed the following code that will extract the icon from an APK file. Note that there is no guarantee about what size the icon will be.
Enjoy!Renaming a dependency JAR before buiding a WAR in Maven
2016-08-05
I was recently tasked with updating New Relic on our servers. When this was initially set up, the server was set up with a JVM command line option:
Here is the plugins section of the working pom.xml:
You do not need to include this dependency in your dependencies section, unless you are actually using it in your code.
We changed the server's JVM command line option to:
-javaagent:/usr/share/tomcat7/webapps/ROOT/WEB-INF/lib/newrelic-3.9.0.jar
When working on updating the version, I wanted to change this so that- We could update the New Relic Agent whenever a new update is available
- We would not need to change the JVM command line each time the Agent was updated
maven-dependency-plugin through a web search, but ran across a problem where my WAR file was being created before the JAR was downloaded and renamed (using maven-war-plugin). All the examples I ran across used <phase>package</phase>, and while that looked right, I figured that this was still happening in the wrong life cycle phase for what I wanted to do. I resorted to reading the documentation, and with some experimenting found that <phase>prepare-package</phase> did this at the right part of the life cycle.
Here is the plugins section of the working pom.xml:
You do not need to include this dependency in your dependencies section, unless you are actually using it in your code.
We changed the server's JVM command line option to:
-javaagent:/usr/share/tomcat7/webapps/ROOT/WEB-INF/lib/newrelic.jar
And everything worked just great ... once I got the YAML file figured out 😉.
Bonus Notes
- If you have not worked with YAML before, you will find out quickly that indentation is important to keep the hierarchy of properties right
- The
newrelic.ymlfile included as an example in thenewrelic-java.zipfile appears to have an error in it. Specifically, theclassloader_excludesproperty values need to be a commented list on the same line. I got parse errors using the example as-is (i.e., the list is indented with each item on a separate line, and has an extra comma at the end). - If you are reading this and setting up a new configuration based on this article, you will also need the
newrelic.ymlfile to end up in the same folder. To that end, place the file in/src/main/webapp/WEB-INF/libin your Maven-based folder structure.
IntelliJ Idea: Can't find gems in Cucumber configurations when using RVM Ruby
2016-07-27
I had updated Ruby on my Mac OS X laptop using RVM:
In IntelliJ IDEA Ultimate 2016, I changed my Cucumber configuration to use the "RVM: ruby-2.3.0" SDK.
I then got any number of errors regarding not having gems installed like cucumber, any of the required gems, and then finally the debug gems (ruby-debug-ide and debase).
Initially, I had some success getting rid of errors one by one by manually running "gem install" on the command line for every gem that was missing. However, in the end, I still had the problems with the debug gems not being installed, and getting errors when attempting to have IntelliJ install the debug gems itself.
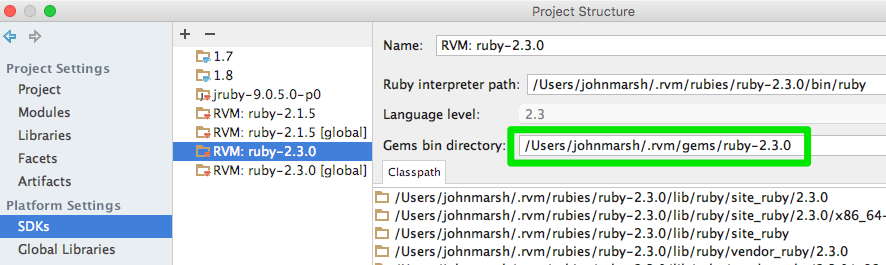
I finally figured out that the Gems bin directory was incorrect. When I when to
and changed Gems bin directory to
Then things started working just fine.


curl -sSL https://get.rvm.io | bash -s stable --ruby
rvm use 2.3 --default
In IntelliJ IDEA Ultimate 2016, I changed my Cucumber configuration to use the "RVM: ruby-2.3.0" SDK.
I then got any number of errors regarding not having gems installed like cucumber, any of the required gems, and then finally the debug gems (ruby-debug-ide and debase).
Run Configuration Error: Cucumber Gem isn't installed for RVM
Initially, I had some success getting rid of errors one by one by manually running "gem install" on the command line for every gem that was missing. However, in the end, I still had the problems with the debug gems not being installed, and getting errors when attempting to have IntelliJ install the debug gems itself.
I finally figured out that the Gems bin directory was incorrect. When I when to
File ➜ ProjectStructure ➜ SDKs ➜ RVM: ruby-2.3.0
and changed Gems bin directory to
/Users/[username]/.rvm/gems/ruby-2.3.0
Then things started working just fine.

Finagle Filter path with "andThen"
2015-12-11
In way of passing on what I am continuing to learn about chained Finagle Filters in Scala:
Filters can be chained together with the “andThen” function. This is essentially an indicator of which direction the Request (input) is handed off to the next filter. I believe that when we normally think about filters, we expect the filter to act on the Request (like a sieve, for example), and indeed it can. However, once the Request gets to the end of the Filter chain, it gets turned into a Response (output), which also, in turn, can be filtered as it is passed back back to the beginning of the Filter chain.
Here is a ScalaTest that shows how both the inward and outward paths can be used to modify the request and the response, as well as a short-circuit in Filter3 that prevents Filter4 from being run (you can change the condition to true to see the path through all four filters). The example Finagle Service here simply takes an initial value and concatenates the request to make a Response:
The console output is:
Promise@71098046(state=Done(Return(start » enter-1 » enter-2 » enter-3 » short-circuit-3 » exit-2 » exit-1)))
And when val myCondition = true :
Promise@380962452(state=Done(Return(Service A:start » enter-1 » enter-2 » enter-3 » enter-4 » exit-4 » exit-3 » exit-2 » exit-1)))
Filters can be chained together with the “andThen” function. This is essentially an indicator of which direction the Request (input) is handed off to the next filter. I believe that when we normally think about filters, we expect the filter to act on the Request (like a sieve, for example), and indeed it can. However, once the Request gets to the end of the Filter chain, it gets turned into a Response (output), which also, in turn, can be filtered as it is passed back back to the beginning of the Filter chain.
Here is a ScalaTest that shows how both the inward and outward paths can be used to modify the request and the response, as well as a short-circuit in Filter3 that prevents Filter4 from being run (you can change the condition to true to see the path through all four filters). The example Finagle Service here simply takes an initial value and concatenates the request to make a Response:
import com.twitter.finagle.{Service, SimpleFilter}
import com.twitter.util.Future
import org.scalatest._
class StringService(response: String) extends Service[String, String] {
override def apply(request: String): Future[String] = Future.value(response + ":" + request)
}
object StringFilter1 extends SimpleFilter[String, String] {
override def apply(request: String, service: Service[String, String]): Future[String] = {
val requestUpdate = request.concat(" » enter-1")
service(requestUpdate).map(futureString => futureString.concat(" » exit-1"))
}
}
object StringFilter2 extends SimpleFilter[String, String] {
override def apply(request: String, service: Service[String, String]): Future[String] = {
val requestUpdate = request.concat(" » enter-2")
service(requestUpdate).map(futureString => futureString.concat(" » exit-2"))
}
}
object StringFilter3 extends SimpleFilter[String, String] {
override def apply(request: String, service: Service[String, String]): Future[String] = {
val requestUpdate = request.concat(" » enter-3")
val myCondition = false
if(myCondition){
service(requestUpdate).map(futureString => futureString.concat(" » exit-3"))
} else {
Future(requestUpdate.concat(" » short-circuit-3"))
}
}
}
object StringFilter4 extends SimpleFilter[String, String] {
override def apply(request: String, service: Service[String, String]): Future[String] = {
val requestUpdate = request.concat(" » enter-4")
service(requestUpdate).map(futureString => futureString.concat(" » exit-4"))
}
}
class FilterStackTest extends FlatSpec with Matchers {
"A Filter" should "Operate like a Stack" in {
var testService = new StringService("Service A")
var testFilter = StringFilter1 andThen StringFilter2 andThen StringFilter3 andThen StringFilter4
System.out.println(testFilter("start",testService))
}
}
The console output is:
Promise@71098046(state=Done(Return(start » enter-1 » enter-2 » enter-3 » short-circuit-3 » exit-2 » exit-1)))
And when val myCondition = true :
Promise@380962452(state=Done(Return(Service A:start » enter-1 » enter-2 » enter-3 » enter-4 » exit-4 » exit-3 » exit-2 » exit-1)))